
Defining & Measuring Software Quality Attributes at Scale
Managing a largely decoupled microservices-based system is always a challenge. We all have maintained an unpleasant bug tracker at some point or the other. Around a year back, when we witnessed a growth spurt, we felt a need for systematically tracking our production systems to capture the live performance of our products and any issues our clients might be facing. It is important to know what your end-users will face when using your products.
The problem with microservices is that the point of failure is not easily detected. A simple solution to this is a tracking id associated with every request. But, if you have already built a production system with hundreds of fully functioning microservices, adding a tracking id requires an unfortunate amount of code changes that may or may not change the code logic.
Also, we noticed that a majority of issues in our systems were not being reported. End-users frequently decide that it is easier to repeat the software activity rather than identifying & reporting the issues. A user may first think — “Probably I made a mistake & did not use the product correctly!”, “It was a glitch, just retry!”.
“Our job as software engineers should be more than writing code, but proactively identifying customer needs & make their experience better.”
Our Solution
Initial Thoughts
If you don’t assign a quantitative value to a parameter, you can’t track it and you can’t improve on it. Evidently, any parameter talked about in qualitative terms is as good as nothing.
Quality improvement is a branch of the larger umbrella of Quality Assurance. QI emphasizes on setting up the right parametric measures during the development and release stages, which will eventually help you measure how your system performs in the real world. Getting the actual data from the real world gives you insights on how your software is getting used outside the lab conditions (your development center).
We wrote an interesting article about one of our large implementations replacing legacy banking systems, which is expected to work in rural areas of India. see section World is not the cozy laboratory, we know that!. The article emphasizes on understanding your last mile user data & build for that.
Software Quality Attributes
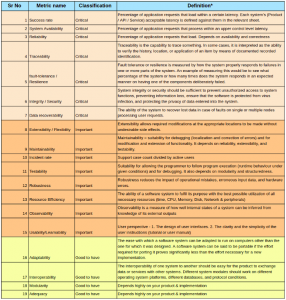
When we first thought of creating such a system at Signzy, the first thing we addressed is the identification of Software Quality Attributes relevant to our systems which we are going to capture and improve upon. It is also advisable to classify them based on their criticality in your systems & impact it would have on your business if the said metrics decline.
An exhaustive list of system quality attributes in Software engineering can be found here.
We chose the below metrics and created definitions for each. While they are mostly standard, it should be noted that input and measured parameters can be customized to fit your needs. For instance, we changed the calculation methodology (which is intentionally omitted in the below table) for 4 of the metrics to fit an API & SaaS software we create.
To see more click
StatusCode
Assigning an intensity helps act as a weighting parameter to map requests that your system processes. A status code that has a higher intensity will make way to the team’s attention faster than the ones with lower intensity.
Success
These are the response codes that are in cases of successful responses. 200 series.
Neutral
Consists of requests that are neutral, but an increase in them either implies there a lot of requests your clients are making which aren’t really relevant. In API business this can be a significant indication of a bad integration experience of your clients. Consists of 300 and 400 series of status codes.
Failures
Include 499 and 500 series, the usual suspects of system failure.
Implementation
There are various standard mechanisms to capture the data required, the most common ways are through:
- Application log files
- Web server request logs
The easiest way is to use the web server’s log files, transfer them in a batch mode to a central system for indexing, processing & analytics. Out of the box services like the Elastic Stack (Elastic, Logstash, Kibana, Filebeat), Prometheus Grafana stack and multiple others help capture relevant data easily and also provide query engines to generate insightful reports.
We implemented our monitoring system by transferring Nginx (our Web Server & Load balancer) log files to the ElasticSearch pipeline using Filebeat. The pipeline parses the data into the Elastic search index which can eventually be used for carrying out insightful analytics.
access_log /var/log/nginx/access-capture.log logstash;
log_format addHeaderlog '$remote_addr $remote_user
$time_local "$request" $status $body_bytes_sent "$http_referer"
"$http_user_agent" "$http_x_forwarded_for" "$request_body"
"$http_Authorization" "$http_x_duid" "$http_x_ver" "$upstream_http_x_rqid"
$request_time $upstream_connect_time $upstream_header_time
$upstream_response_time "-" "-"';
Correspondingly the pipeline on elastic search can look like the below.
// Below request as the elastic search query
// for getting your pipeline information
GET _ingest/pipeline/my-pipeline
// for creating/updating the pipelines
PUT _ingest/pipeline/my-pipeline
// Refer elasticsearch (ELK) 7.2+ documentations for more details
{
"my-pipeline" : {
"description" : "Pipeline for nginx access.log file",
"processors" : [
{
"grok" : {
"field" : "message",
"patterns" : [
"%{DATA:remoteAddress} %{DATA:remoteUser} %
{HAPROXYDATE:requestTimestamp} %{QS:request} %{NUMBER:statusCode} %
{NUMBER:bodyBytesSent} %{QS:httpReferrer} %{QS:httpUserAgent} %
{QS:httpXForwardedFor} %{QS:requestBody} %{QS:requestAuth} %{QS:httpXDuid}%
{QS:httpXVer} %{QS:httpXRqid} %{DATA:requestTime} %
{DATA:upstreamConnectTime} %{DATA:upstreamHeaderTime} %
{DATA:upstreamResponseTime} %{QS:responseBody} %{QS:greedyData}"
],
"on_failure" : [
{
"set" : {
"field" : "errorMessage",
"value" : "{{ _ingest.on_failure_message }}"
}
}
]
}
}
]
}
}
File beat can be configured to send data to elastic search pipeline using a configuration similar to below:
Edit configuration file, filebeat.yml:
$ sudo vim /etc/filebeat/filebeat.yml
And insert configuration like below:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
output.elasticsearch:
hosts: ["log.server:32121"]
pipeline: nginx-grok-1
setup.kibana:
host: "log.server:32122"
** Please ensure the logs do not contain any sensitive data.
While the logs getting passed into a central system facilitates as a fast, efficient and live method of identifying issues, it has to be ensured that the logs don’t contain any personally identifiable data for your customers. The log processing systems, in general, are not designed to focus on security but rather on faster processing on telemetry data. You will have to ensure security.
Once the data has arrived in your analytics system, you can conduct a plethora of analytics and calculations to help you measure your system’s performance. An example would be a simple query like the below that aggregates based on response codes.
Query
GET filebeat-*/_search
{
"size": 0,
"query": {
"bool": {
"must": [
{
"range": {
"@timestamp": {
"format": "strict_date_optional_time",
"gte": "now-1d/d",
"lte": "now/d"
}
}
}
],
"filter": [
{
"match_all": {}
}
],
"should": [],
"must_not": []
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "statusCode.keyword"
}
}
}
}
Output
{
"took" : 1656,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3488,
"buckets" : [
{
"key" : "200",
"doc_count" : 3316229
},
{
"key" : "405",
"doc_count" : 50592
},
{
"key" : "422",
"doc_count" : 22977
},
{
"key" : "400",
"doc_count" : 15295
},
{
"key" : "201",
"doc_count" : 10839
},
{
"key" : "404",
"doc_count" : 8353
},
{
"key" : "500",
"doc_count" : 2305
},
{
"key" : "403",
"doc_count" : 1929
},
{
"key" : "410",
"doc_count" : 1626
},
{
"key" : "204",
"doc_count" : 904
}
]
}
}
}
Let’s say you want to calculate the response time percentiles, a query like below can instantly provide a relevant output that you can filter.
Query
GET filebeat-*/_search
{
"size": 0,
"query": {
"bool": {
"must": [{
"range": {
"@timestamp": {
"format": "strict_date_optional_time",
"gte": "now-1d/d",
"lte": "now/d"
}
}
}
],
"filter": [
{
"match_all": {}
}
],
"should": [],
"must_not": []
}
},
"aggs": {
"requestTime": {
"range": {
"script": "(doc['requestTime.keyword'].size()>0 && doc['requestTime.keyword'].value != null && doc['requestTime.keyword'].value != '-' ? Double.parseDouble(doc['requestTime.keyword'].value) : 0)",
"ranges": [
{"to": "0.5"},
{"from": "0.5", "to":"1.0"},
{"from": "1.0", "to":"1.5"},
{"from": "1.5", "to":"2.0"},
{"from": "2.0", "to":"2.5"},
{"from": "2.5", "to":"3.0"},
{"from":"3.0"}
]
}
Output
{
"took" : 1832,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"requestTime" : {
"buckets" : [
{
"key" : "*-0.5",
"to" : 0.5,
"doc_count" : 2775431
},
{
"key" : "0.5-1.0",
"from" : 0.5,
"to" : 1.0,
"doc_count" : 62018
},
{
"key" : "1.0-1.5",
"from" : 1.0,
"to" : 1.5,
"doc_count" : 25563
},
{
"key" : "1.5-2.0",
"from" : 1.5,
"to" : 2.0,
"doc_count" : 98898
},
{
"key" : "2.0-2.5",
"from" : 2.0,
"to" : 2.5,
"doc_count" : 108635
},
{
"key" : "2.5-3.0",
"from" : 2.5,
"to" : 3.0,
"doc_count" : 61629
},
{
"key" : "3.0-*",
"from" : 3.0,
"doc_count" : 314262
}
]
}
}
}
You may also use a variety of aggregations provided by ElasticSearch, for instance, percentile aggregations on numeric values.
Always use production data only to do quality improvement measurements and improvements. That’s the only way you see what your users see.
Results
We successfully identified and fixed 96% production bugs and learned a great deal about our legacy codebase. It served as an eye-opening experience for our tech team and continues to help us improve our code quality
Use Cases
- Detecting and fixing production anomalies
- Monitoring system changes after every deployment
- Growing our test case scenarios with observed patterns
- Visualizing our production load and accordingly scaling our system
Insights
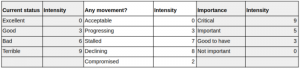
It is important to create an executive report detailing how you are doing on your quality attributes. As always assign intensities to your statuses which will help you derive a holistic view of your system’s quality. The below methodology can give you guidelines to answer questions like:
- What is the current status of your metric?
- Whether it is progressing, stalled or compromised, etc?
- Default intensity values assigned to the critical, important and good to have metrics.
As experts say, find bugs early before they bite you back, and rightly so.
The below article treats the importance of identifying issues as early as possible & how costly issues can be if not identified early.
About Signzy
Signzy is a market-leading platform redefining the speed, accuracy, and experience of how financial institutions are onboarding customers and businesses – using the digital medium. The company’s award-winning no-code GO platform delivers seamless, end-to-end, and multi-channel onboarding journeys while offering customizable workflows. In addition, it gives these players access to an aggregated marketplace of 240+ bespoke APIs that can be easily added to any workflow with simple widgets.
Signzy is enabling ten million+ end customer and business onboarding every month at a success rate of 99% while reducing the speed to market from 6 months to 3-4 weeks. It works with over 240+ FIs globally, including the 4 largest banks in India, a Top 3 acquiring Bank in the US, and has a robust global partnership with Mastercard and Microsoft. The company’s product team is based out of Bengaluru and has a strong presence in Mumbai, New York, and Dubai.
Visit www.signzy.com for more information about us.
You can reach out to our team at reachout@signzy.com
Written By:
Ankur and Prakriti
Spread the knowledge!
Found this useful ? Share what you learned!

